를 사용한 BFS (Breadth First Search) 알고리즘 BFS 알고리즘 (Breadth-First Search)이란 무엇입니까?
BFS (Breadth-First Search)는 데이터를 그래프로 표시하거나 트리를 검색하거나 구조를 탐색하는 데 사용되는 알고리즘입니다. BFS의 전체 형태는 Breadth-first 검색입니다.
알고리즘은 정확한 폭의 방식으로 그래프의 모든 주요 노드를 효율적으로 방문하고 표시합니다. 이 알고리즘은 그래프에서 단일 노드 (초기 또는 소스 지점)를 선택한 다음 선택한 노드에 인접한 모든 노드를 방문합니다. BFS는 이러한 노드에 하나씩 액세스합니다.
알고리즘이 시작 노드를 방문하고 표시하면 가장 가까운 방문하지 않은 노드로 이동하여 분석합니다. 방문하면 모든 노드가 표시됩니다. 이러한 반복은 그래프의 모든 노드를 성공적으로 방문하고 표시 할 때까지 계속됩니다.
이 알고리즘 자습서에서는 다음을 학습하게됩니다.
- BFS 알고리즘 (Breadth-First Search)이란 무엇입니까?
- 그래프 순회 란 무엇입니까?
- BFS 알고리즘 아키텍처
- BFS 알고리즘이 필요한 이유는 무엇입니까?
- BFS 알고리즘은 어떻게 작동합니까?
- BFS 알고리즘 예제
- BFS 알고리즘 규칙
- BFS 알고리즘 응용 프로그램
그래프 순회 란 무엇입니까?
그래프 순회는 그래프에서 정점 위치를 찾는 데 일반적으로 사용되는 방법입니다. 방문한 꼭지점의 순서를 표시하고 속도와 정밀도로 그래프를 분석 할 수있는 고급 검색 알고리즘입니다. 이 프로세스를 통해 무한 루프에 고정되지 않고 그래프의 각 노드를 빠르게 방문 할 수 있습니다.
BFS 알고리즘의 아키텍처
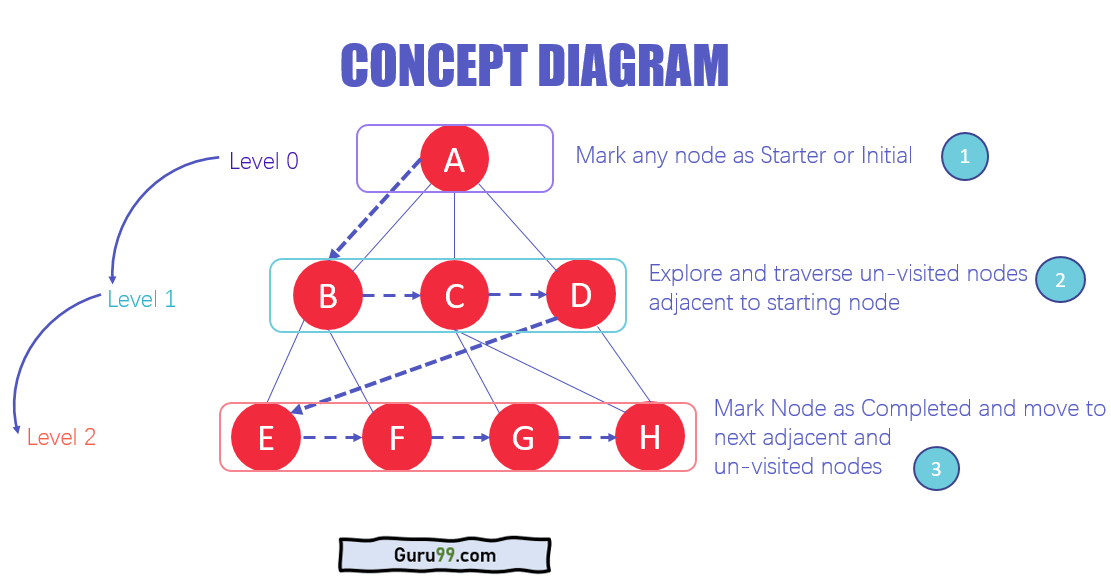
- 데이터의 다양한 수준에서 모든 노드를 시작으로 표시 할 수 있습니다. 또는 순회를 시작하기위한 초기 노드. BFS는 노드를 방문하여 방문한 것으로 표시하고 대기열에 넣습니다.
- 이제 BFS는 가장 가까운 방문하지 않은 노드를 방문하여 표시합니다. 이러한 값은 대기열에도 추가됩니다. 대기열은 FIFO 모델에서 작동합니다.
- 유사한 방식으로 그래프에서 가장 가까운 나머지 노드와 방문하지 않은 노드가 분석되어 표시되고 대기열에 추가됩니다. 이러한 항목은 수신시 대기열에서 삭제되고 결과로 인쇄됩니다.
BFS 알고리즘이 필요한 이유는 무엇입니까?
BFS 알고리즘을 데이터 세트 검색에 사용하는 데는 여러 가지 이유가 있습니다. 이 알고리즘을 첫 번째 선택으로 만드는 가장 중요한 측면 중 일부는 다음과 같습니다.
- BFS는 그래프의 노드를 분석하고이를 통과하는 최단 경로를 구성하는 데 유용합니다.
- BFS는 가장 적은 수의 반복으로 그래프를 순회 할 수 있습니다.
- BFS 알고리즘의 아키텍처는 간단하고 강력합니다.
- BFS 알고리즘의 결과는 다른 알고리즘에 비해 높은 수준의 정확도를 유지합니다.
- BFS 반복은 매끄럽고이 알고리즘이 무한 루프 문제에 휘말릴 가능성이 없습니다.
BFS 알고리즘은 어떻게 작동합니까?
그래프 순회를 위해서는 알고리즘이 트리와 같은 구조의 방문하지 않은 모든 노드를 방문, 확인 및 / 또는 업데이트해야합니다. 그래프 순회는 그래프의 노드를 방문하는 순서에 따라 분류됩니다.
BFS 알고리즘은 그래프의 첫 번째 노드 또는 시작 노드에서 작업을 시작하고 철저하게 순회합니다. 초기 노드를 성공적으로 통과하면 그래프의 다음 비 순회 정점을 방문하여 표시합니다.
따라서 현재 정점에 인접한 모든 노드가 첫 번째 반복에서 방문되고 순회되었다고 말할 수 있습니다. 간단한 대기열 방법론은 BFS 알고리즘의 작동을 구현하는 데 사용되며 다음 단계로 구성됩니다.
1 단계)

그래프의 각 정점 또는 노드가 알려져 있습니다. 예를 들어 노드를 V로 표시 할 수 있습니다.
2 단계)

V 정점에 액세스하지 않은 경우 정점 V를 BFS 대기열에 추가합니다.
3 단계)

BFS 검색을 시작하고 완료 후 꼭지점 V를 방문한 것으로 표시합니다.
4 단계)

BFS 대기열은 여전히 비어 있지 않으므로 대기열에서 그래프의 정점 V를 제거합니다.
5 단계)

나머지 모든 꼭지점 검색 정점 V에 인접한 그래프에서
6 단계)

인접한 각 정점에 대해 “V1″이라고 말하고 아직 방문하지 않은 경우 BFS 대기열에 V1을 추가합니다.
7 단계)

BFS는 V1을 방문하여 방문한 것으로 표시하고 대기열에서 삭제합니다.
BFS 알고리즘 예제
1 단계)

0-6 범위의 7 개 숫자
2 단계)

0 또는 0이 루트 노드로 표시되었습니다.
3 단계)

0을 방문하여 표시하고 대기열 데이터 구조에 삽입합니다.
4 단계)
<디 iv id = "94437aebd2">
남은 0 개의 인접 및 방문하지 않은 노드를 방문하여 표시하고 대기열에 삽입합니다.
5 단계)

모든 노드를 방문 할 때까지 순회 반복이 반복됩니다.
BFS 알고리즘 규칙
다음은 BFS 알고리즘 사용에 대한 중요한 규칙입니다.
- 큐 (FIFO- 선입 선출) 데이터 구조 BFS에서 사용됩니다.
- 그래프의 노드를 루트로 표시하고 여기에서 데이터 탐색을 시작합니다.
- BFS는 그래프의 모든 노드를 탐색하고 완료된 것으로 계속 삭제합니다.
- BFS는 인접한 방문하지 않은 노드를 방문하여 완료로 표시 한 다음 대기열에 삽입합니다.
- 인접한 정점이없는 경우 대기열에서 이전 정점을 제거합니다.
- BFS 알고리즘은 그래프의 모든 정점이 성공적으로 횡단되고 완료된 것으로 표시 될 때까지 반복됩니다.
- 어떤 노드에서든 데이터를 순회하는 동안 BFS로 인한 루프가 없습니다.
BFS 알고리즘의 응용
BFS 알고리즘 구현이 매우 효과적 일 수있는 실제 응용 프로그램을 살펴보십시오.
- 가중치가없는 그래프 : BFS 알고리즘은 모든 사용자를 방문 할 수있는 최단 경로와 최소 스패닝 트리를 쉽게 생성 할 수 있습니다. 최대한 짧은 시간에 그래프의 정점을 높은 정확도로 측정합니다.
- P2P 네트워크 : BFS를 구현하여 P2P 네트워크에서 가장 가까운 노드 나 인접 노드를 모두 찾을 수 있습니다. 이렇게하면 필요한 데이터를 더 빨리 찾을 수 있습니다. .
- 웹 크롤러 : 검색 엔진 또는 웹 크롤러는 BFS를 사용하여 여러 수준의 색인을 쉽게 구축 할 수 있습니다. BFS 구현은 웹 페이지 인 소스에서 시작된 다음 해당 소스의 모든 링크를 방문합니다. .
- 내비게이션 시스템 : BFS는 기본 또는 소스 위치에서 모든 인접 위치를 찾는 데 도움을 줄 수 있습니다.
- 네트워크 브로드 캐스트 ing : 브로드 캐스트 된 패킷은 BFS 알고리즘에 의해 안내되어 주소가있는 모든 노드를 찾아 도달합니다.
요약
- 그래프 순회는 알고리즘에서 방문하지 않은 모든 노드를 방문, 확인 및 / 또는 업데이트해야하는 고유 한 프로세스입니다. 나무와 같은 구조. BFS 알고리즘은 유사한 원리로 작동합니다.
- 알고리즘은 그래프에서 노드를 분석하고이를 통과하는 최단 경로를 구성하는 데 유용합니다.
- 알고리즘은 가장 적은 반복 횟수와 가능한 가장 짧은 시간에 그래프를 순회합니다.
- BFS는 그래프에서 단일 노드 (초기 또는 소스 지점)를 선택한 다음 선택한 노드에 인접한 모든 노드를 방문합니다. BFS는 이러한 노드에 하나씩 액세스합니다.
- 방문하고 표시된 데이터는 BFS에 의해 대기열에 배치됩니다. 대기열은 선입 선출 방식으로 작동합니다. 따라서 그래프에 먼저 배치 된 요소가 먼저 삭제되고 결과적으로 인쇄됩니다.
- BFS 알고리즘은 무한 루프에 빠질 수 없습니다.
- 높은 정밀도와 강력한 구현으로 인해 BFS는 P2P 네트워크, 웹 크롤러, 웹 크롤러와 같은 여러 실제 솔루션에서 사용됩니다. 및 네트워크 방송.