Nota: questo articolo è stato originariamente pubblicato il 10 ottobre 2014 e aggiornato il 27 marzo 2018
Panoramica
- Comprendi k più vicino (KNN), uno degli algoritmi di apprendimento automatico più popolari
- Impara il funzionamento di kNN in python
- Scegli il giusto valore di k in termini semplici
Introduzione
Nei quattro anni della mia carriera nel campo della scienza dei dati, ho costruito più dell80% di modelli di classificazione e solo il 15-20% di modelli di regressione. Questi rapporti possono essere più o meno generalizzati in tutto il settore. Il motivo alla base di questo pregiudizio verso i modelli di classificazione è che la maggior parte dei problemi analitici implica prendere una decisione.
Ad esempio, un cliente attrarrà o meno, se dovessimo indirizzare il cliente X per campagne digitali, indipendentemente dal fatto che il cliente abbia o meno un potenziale elevato, ecc. Queste analisi sono più approfondite e direttamente collegate a una roadmap di implementazione.

In questo articolo parleremo di unaltra tecnica di classificazione di machine learning ampiamente utilizzata chiamata KNN (Near Neighbors). Il nostro focus sarà principalmente su come funziona lalgoritmo e in che modo il parametro di input influisce sulloutput / previsione.
Nota: le persone che preferiscono imparare attraverso i video possono imparare lo stesso attraverso il nostro corso gratuito – K- Algoritmo Nearest Neighbors (KNN) in Python e R. E se sei un principiante assoluto di Data Science e Machine Learning, dai unocchiata al nostro programma Certified BlackBelt –
- Certified AI & ML Blackbelt + Program
Sommario
- Quando utilizziamo lalgoritmo KNN?
- Come funziona il Lalgoritmo KNN funziona?
- Come scegliamo il fattore K?
- Scomponendolo – Pseudo codice di KNN
- Implementazione in Python da zero
- Confronto del nostro modello con scikit-learn
Quando utilizziamo lalgoritmo KNN?
KNN può essere utilizzato per entrambi problemi predittivi di classificazione e regressione. Tuttavia, è più ampiamente utilizzato nei problemi di classificazione nellindustria. Per valutare qualsiasi tecnica, generalmente consideriamo 3 aspetti importanti:
1. Facilità di interpretazione delloutput
2. Tempo di calcolo
3. Potere predittivo
Prendiamo alcuni esempi per inserire KNN nella scala:
 Fiere di algoritmi KNN attraverso tutti i parametri di considerazione. È comunemente usato per la sua facilità di interpretazione e il basso tempo di calcolo.
Fiere di algoritmi KNN attraverso tutti i parametri di considerazione. È comunemente usato per la sua facilità di interpretazione e il basso tempo di calcolo.
Come funziona lalgoritmo KNN?
Facciamo un caso semplice per comprendere questo algoritmo. Di seguito è riportata una serie di cerchi rossi (RC) e quadrati verdi (GS):
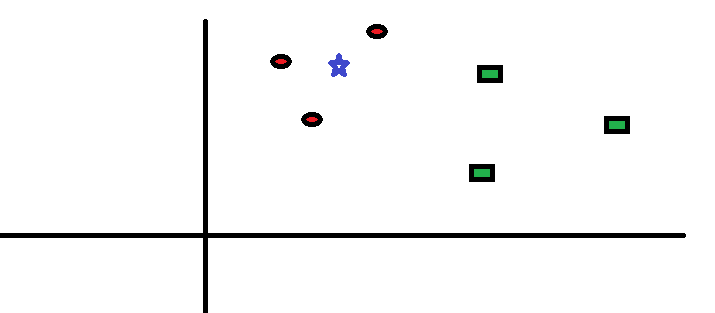 Hai intenzione di scoprirlo la classe della stella blu (BS). BS può essere RC o GS e nientaltro. Lalgoritmo “K” è KNN è il vicino più vicino da cui desideriamo prendere il voto. Diciamo K = 3. Quindi, ora creeremo un cerchio con BS come centro grande tanto da racchiudere solo tre punti dati sul piano . Fare riferimento al diagramma seguente per maggiori dettagli:
Hai intenzione di scoprirlo la classe della stella blu (BS). BS può essere RC o GS e nientaltro. Lalgoritmo “K” è KNN è il vicino più vicino da cui desideriamo prendere il voto. Diciamo K = 3. Quindi, ora creeremo un cerchio con BS come centro grande tanto da racchiudere solo tre punti dati sul piano . Fare riferimento al diagramma seguente per maggiori dettagli:
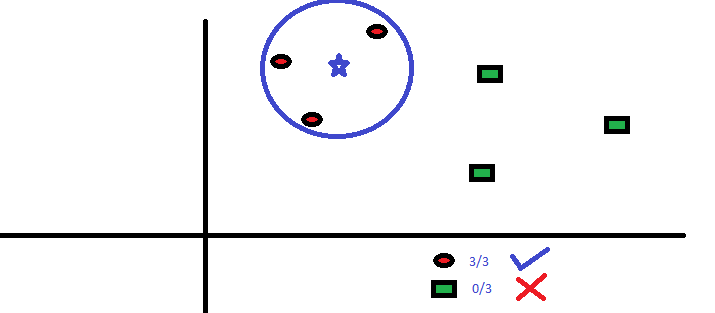 I tre punti più vicini a BS sono tutti RC. Quindi, con un buon livello di confidenza possiamo dire che il BS dovrebbe appartenere alla classe RC. Qui la scelta è diventata molto ovvia in quanto tutti e tre i voti del vicino più prossimo andavano a RC. La scelta del parametro K è molto cruciale in questo algoritmo Successivamente, capiremo quali sono i fattori da considerare per concludere al meglio K.
I tre punti più vicini a BS sono tutti RC. Quindi, con un buon livello di confidenza possiamo dire che il BS dovrebbe appartenere alla classe RC. Qui la scelta è diventata molto ovvia in quanto tutti e tre i voti del vicino più prossimo andavano a RC. La scelta del parametro K è molto cruciale in questo algoritmo Successivamente, capiremo quali sono i fattori da considerare per concludere al meglio K.
Come scegliamo il fattore K?
Per prima cosa cerchiamo di capire cosa esattamente influenza K nellalgoritmo. Se vediamo lultimo esempio, dato che tutte e 6 le osservazioni di allenamento rimangono costanti, con un dato valore di K possiamo fare dei confini di ogni classe. Se confini separeranno RC da GS. Allo stesso modo, proviamo a vedere leffetto del valore “K” sui confini delle classi. Di seguito sono riportati i diversi confini che separano le due classi con valori diversi di K.
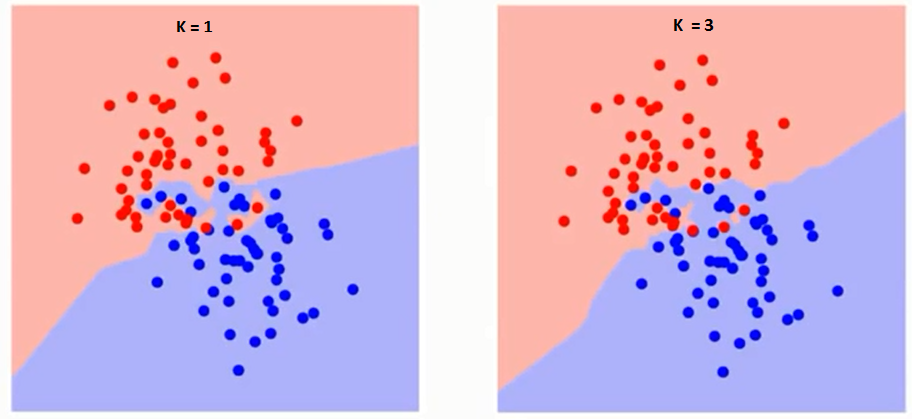
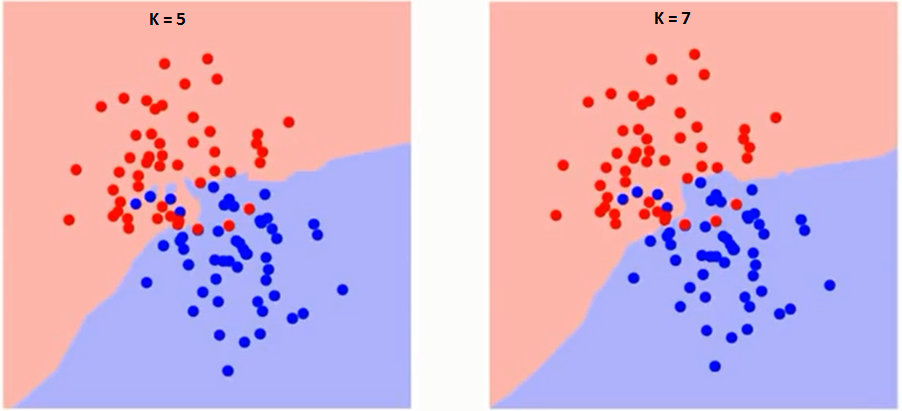
Se guardi attentamente, puoi vedere che il confine diventa più liscio con laumento del valore di K. Con K che aumenta allinfinito diventa finalmente tutto blu o tutto rosso a seconda della maggioranza totale Il tasso di errore di addestramento e il tasso di errore di convalida sono due parametri di cui abbiamo bisogno per accedere a diversi valori di K. Di seguito è riportata la curva per il tasso di errore di addestramento con un valore variabile di K:
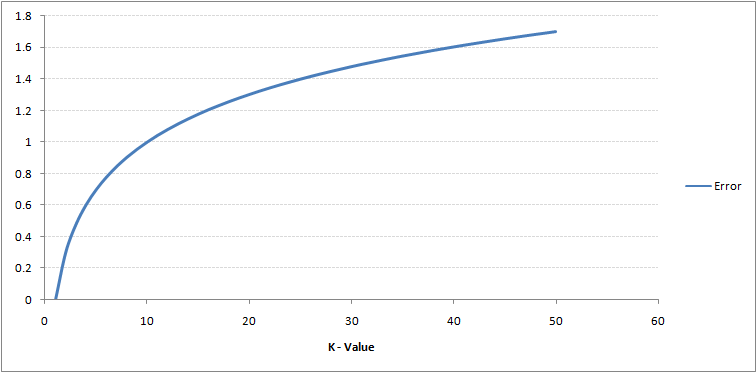 Come puoi vedere, il il tasso di errore a K = 1 è sempre zero per il campione di addestramento.Questo perché il punto più vicino a qualsiasi punto dati di addestramento è se stesso, quindi la previsione è sempre accurata con K = 1. Se la curva di errore di convalida fosse stata simile, la nostra scelta di K sarebbe stata 1. Di seguito è riportata la curva di errore di convalida con valore variabile di K:
Come puoi vedere, il il tasso di errore a K = 1 è sempre zero per il campione di addestramento.Questo perché il punto più vicino a qualsiasi punto dati di addestramento è se stesso, quindi la previsione è sempre accurata con K = 1. Se la curva di errore di convalida fosse stata simile, la nostra scelta di K sarebbe stata 1. Di seguito è riportata la curva di errore di convalida con valore variabile di K:
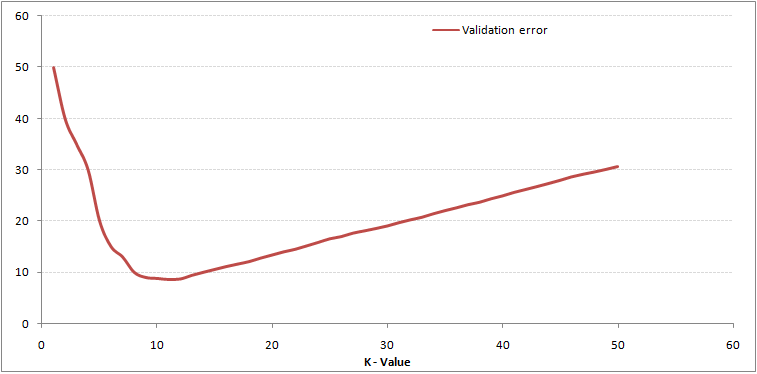 Questo rende la storia più chiara. A K = 1, stavamo superando i limiti. Quindi, il tasso di errore inizialmente diminuisce e raggiunge un minimo. Dopo il punto minimo, aumenta con laumento di K. Per ottenere il valore ottimale di K, è possibile separare laddestramento e la convalida dal set di dati iniziale. Ora traccia la curva di errore di convalida per ottenere il valore ottimale di K. Questo valore di K dovrebbe essere utilizzato per tutte le previsioni.
Questo rende la storia più chiara. A K = 1, stavamo superando i limiti. Quindi, il tasso di errore inizialmente diminuisce e raggiunge un minimo. Dopo il punto minimo, aumenta con laumento di K. Per ottenere il valore ottimale di K, è possibile separare laddestramento e la convalida dal set di dati iniziale. Ora traccia la curva di errore di convalida per ottenere il valore ottimale di K. Questo valore di K dovrebbe essere utilizzato per tutte le previsioni.
Il contenuto di cui sopra può essere compreso in modo più intuitivo utilizzando il nostro corso gratuito – K-Nearest Neighbors ( KNN) Algoritmo in Python e R
Scomponendolo – Pseudo Codice di KNN
Possiamo implementare un modello KNN seguendo i passaggi seguenti:
- Carica i dati
- Inizializza il valore di k
- Per ottenere la classe prevista, itera da 1 al numero totale di punti dati di addestramento
- Calcola la distanza tra i test dati e ogni riga di dati di addestramento. Qui useremo la distanza euclidea come metrica della distanza poiché è il metodo più popolare. Le altre metriche che possono essere utilizzate sono Chebyshev, coseno, ecc.
- Ordina le distanze calcolate in ordine crescente in base ai valori di distanza
- Ottieni le prime k righe dallarray ordinato
- Ottieni la classe più frequente di queste righe
- Restituisci la classe prevista
Implementazione in Python da zero
Useremo il popolare dataset Iris per costruire il nostro modello KNN. Puoi scaricarlo da qui.
Confrontando il nostro modello con scikit-learn
Possiamo vedere che entrambi i modelli predicevano la stessa classe (Iris- virginica ) e gli stessi vicini più prossimi (). Quindi possiamo concludere che il nostro modello funziona come previsto.
Implementazione di kNN in R
Passaggio 1: importazione dei dati
Passaggio 2: controllo dei dati e calcolo del riepilogo dei dati
Output
Passaggio 3: suddivisione dei dati
Passaggio 4: calcolo la distanza euclidea
Passaggio 5: scrittura della funzione per prevedere kNN
Passaggio 6: calcolo delletichetta (Nome) per K = 1
Risultato
For K=1 "Iris-virginica"
Allo stesso modo, puoi calcolare altri valori di K.
Confrontando la nostra funzione predittore kNN con la libreria “Class”
Output
For K=1 "Iris-virginica"
Possiamo vedere che entrambi modelli prevedevano la stessa classe (“Iris-virginica”).
Note finali
Lalgoritmo KNN è uno degli algoritmi di classificazione più semplici. Anche con tale semplicità, può dare risultati altamente competitivi, lalgoritmo KNN può essere utilizzato anche per problemi di regressione, unica differenza dalla metodologia discussa si utilizzerà la media dei vicini più vicini piuttosto che il voto dei vicini più vicini. KNN può essere codificato in una singola riga su R. Devo ancora esplorare come possiamo utilizzare lalgoritmo KNN su SAS.
Hai trovato utile larticolo? Hai usato di recente qualche altro strumento di apprendimento automatico? Prevedi di utilizzare KNN in uno dei tuoi problemi aziendali? Se sì, condividi con noi come pensi di procedere.