Nota: Este artículo se publicó originalmente el 10 de octubre de 2014 y se actualizó el 27 de marzo de 2018
Descripción general
- Comprender k vecino más cercano (KNN), uno de los algoritmos de aprendizaje automático más populares
- Aprender el funcionamiento de kNN en python
- Elija el valor correcto de k en términos simples
Introducción
En los cuatro años de mi carrera en ciencia de datos, he construido más del 80% de modelos de clasificación y solo un 15-20% de modelos de regresión. Estas proporciones pueden estar más o menos generalizadas en toda la industria. La razón detrás de este sesgo hacia los modelos de clasificación es que la mayoría de los problemas analíticos implican tomar una decisión.
Por ejemplo, si un cliente se desgastará o no, si nos dirigimos al cliente X campañas digitales, ya sea que el cliente tenga un alto potencial o no, etc. Estos análisis son más reveladores y están directamente vinculados a una hoja de ruta de implementación.

En este artículo, hablaremos sobre otra técnica de clasificación de aprendizaje automático ampliamente utilizada llamada K-vecinos más cercanos (KNN). Nuestro enfoque estará principalmente en cómo funciona el algoritmo y cómo el parámetro de entrada afecta la salida / predicción.
Nota: Las personas que prefieren aprender a través de videos pueden aprender lo mismo a través de nuestro curso gratuito – K- Algoritmo de vecinos más cercanos (KNN) en Python y R. Y si es un principiante completo en ciencia de datos y aprendizaje automático, consulte nuestro programa Certified BlackBelt:
- AI certificada & Programa ML Blackbelt +
Tabla de contenido
- ¿Cuándo usamos el algoritmo KNN?
- ¿Cómo ¿Funciona el algoritmo KNN?
- ¿Cómo elegimos el factor K?
- Desglosando: pseudocódigo de KNN
- Implementación en Python desde cero
- Comparando nuestro modelo con scikit-learn
¿Cuándo usamos el algoritmo KNN?
KNN se puede usar para ambos problemas predictivos de clasificación y regresión. Sin embargo, se usa más ampliamente en problemas de clasificación en la industria. Para evaluar cualquier técnica, generalmente nos fijamos en 3 aspectos importantes:
1. Fácil de interpretar la salida
2. Tiempo de cálculo
3. Poder predictivo
Tomemos algunos ejemplos para colocar KNN en la escala:
 Ferias de algoritmos KNN en todos los parámetros de consideraciones. Se usa comúnmente por su fácil interpretación y bajo tiempo de cálculo.
Ferias de algoritmos KNN en todos los parámetros de consideraciones. Se usa comúnmente por su fácil interpretación y bajo tiempo de cálculo.
¿Cómo funciona el algoritmo KNN?
Tomemos un caso simple para entender este algoritmo. A continuación se muestra una extensión de círculos rojos (RC) y cuadrados verdes (GS):
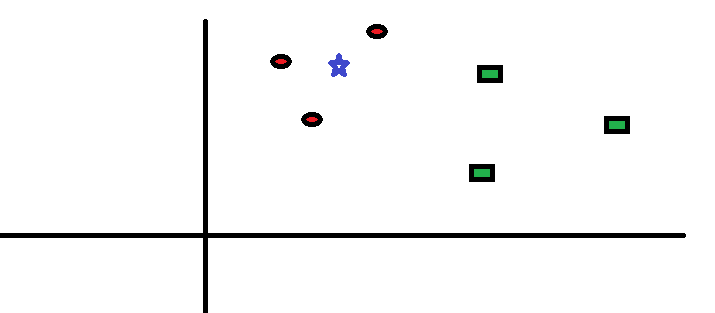 Tiene la intención de averiguarlo la clase de la estrella azul (BS). BS puede ser RC o GS y nada más. El algoritmo «K» es KNN es el vecino más cercano al que deseamos votar. Digamos que K = 3. Por lo tanto, ahora haremos un círculo con BS como centro tan grande como para encerrar solo tres puntos de datos en el plano . Consulte el siguiente diagrama para obtener más detalles:
Tiene la intención de averiguarlo la clase de la estrella azul (BS). BS puede ser RC o GS y nada más. El algoritmo «K» es KNN es el vecino más cercano al que deseamos votar. Digamos que K = 3. Por lo tanto, ahora haremos un círculo con BS como centro tan grande como para encerrar solo tres puntos de datos en el plano . Consulte el siguiente diagrama para obtener más detalles:
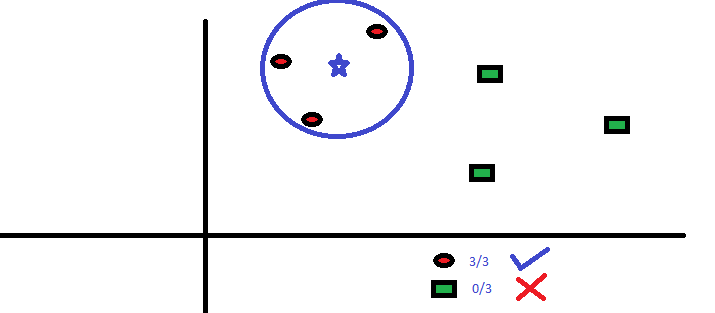 Los tres puntos más cercanos a BS son todos RC. Por lo tanto, con un buen nivel de confianza, podemos decir que el BS debería pertenecer a la clase RC. Aquí, la elección se hizo muy obvia ya que los tres votos del vecino más cercano fueron a RC. La elección del parámetro K es muy crucial en este algoritmo A continuación, entenderemos cuáles son los factores a considerar para concluir mejor K.
Los tres puntos más cercanos a BS son todos RC. Por lo tanto, con un buen nivel de confianza, podemos decir que el BS debería pertenecer a la clase RC. Aquí, la elección se hizo muy obvia ya que los tres votos del vecino más cercano fueron a RC. La elección del parámetro K es muy crucial en este algoritmo A continuación, entenderemos cuáles son los factores a considerar para concluir mejor K.
¿Cómo elegimos el factor K?
Primero tratemos de entender qué influencia exactamente K en el algoritmo. Si vemos el último ejemplo, dado que las 6 observaciones de entrenamiento permanecen constantes, con un valor de K dado podemos establecer límites para cada clase. Estos límites segregarán RC de GS. De la misma manera, intentemos ver el efecto del valor «K» en los límites de la clase. A continuación, se muestran los diferentes límites que separan las dos clases con diferentes valores de K.
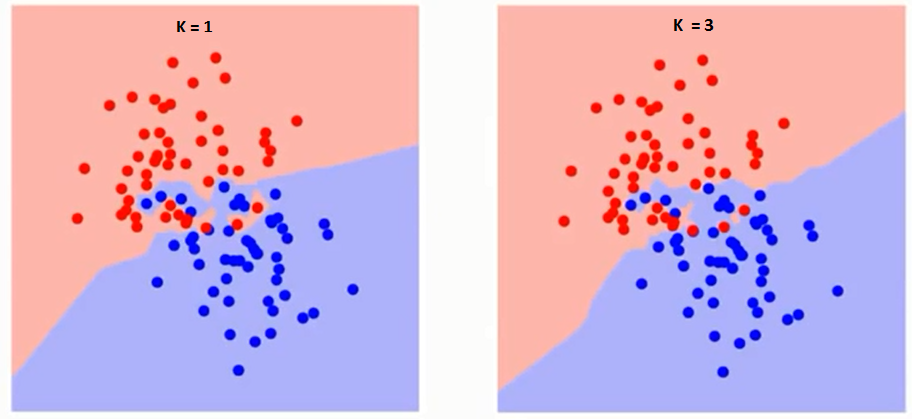
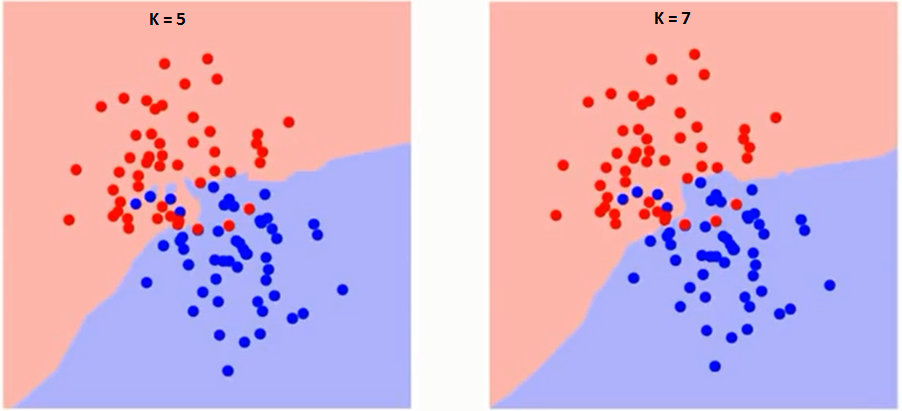
Si miras con atención, puedes ver que el límite se vuelve más suave al aumentar el valor de K. Con el aumento de K hasta el infinito, finalmente se vuelve todo azul o todo rojo dependiendo de la mayoría total. La tasa de error de entrenamiento y la tasa de error de validación son dos parámetros que necesitamos para acceder a diferentes valores de K. A continuación se muestra la curva de la tasa de error de entrenamiento con un valor variable de K:
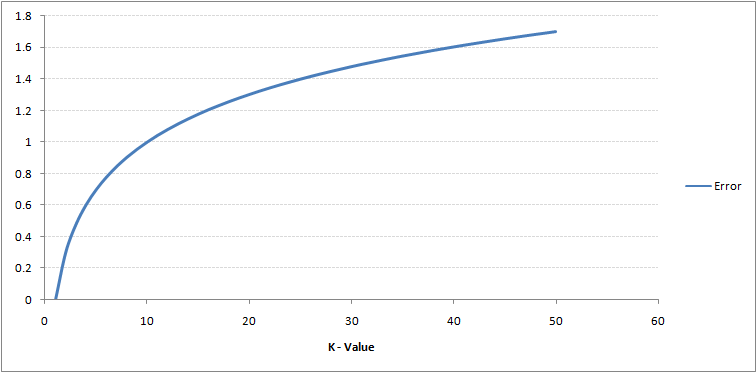 Como puede ver, el La tasa de error en K = 1 es siempre cero para la muestra de entrenamiento.Esto se debe a que el punto más cercano a cualquier punto de datos de entrenamiento es él mismo, por lo que la predicción siempre es precisa con K = 1. Si la curva de error de validación hubiera sido similar, nuestra elección de K habría sido 1. A continuación se muestra la curva de error de validación con un valor variable de K:
Como puede ver, el La tasa de error en K = 1 es siempre cero para la muestra de entrenamiento.Esto se debe a que el punto más cercano a cualquier punto de datos de entrenamiento es él mismo, por lo que la predicción siempre es precisa con K = 1. Si la curva de error de validación hubiera sido similar, nuestra elección de K habría sido 1. A continuación se muestra la curva de error de validación con un valor variable de K:
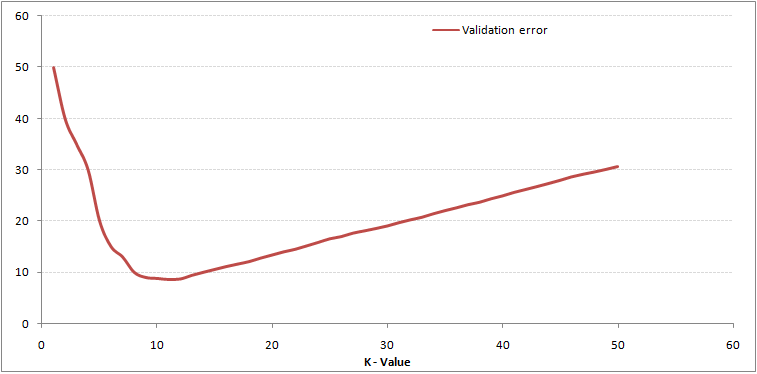 Esto aclara la historia. En K = 1, estábamos sobreajustando los límites. Por lo tanto, la tasa de error inicialmente disminuye y alcanza un mínimo. Después del punto mínimo, aumenta a medida que aumenta K. Para obtener el valor óptimo de K, puede segregar el entrenamiento y la validación del conjunto de datos inicial. Ahora trace la curva de error de validación para obtener el valor óptimo de K. Este valor de K debe usarse para todas las predicciones.
Esto aclara la historia. En K = 1, estábamos sobreajustando los límites. Por lo tanto, la tasa de error inicialmente disminuye y alcanza un mínimo. Después del punto mínimo, aumenta a medida que aumenta K. Para obtener el valor óptimo de K, puede segregar el entrenamiento y la validación del conjunto de datos inicial. Ahora trace la curva de error de validación para obtener el valor óptimo de K. Este valor de K debe usarse para todas las predicciones.
El contenido anterior se puede entender de manera más intuitiva usando nuestro curso gratuito: K-Vecinos más cercanos ( KNN) Algoritmo en Python y R
Desglosando – Pseudo código de KNN
Podemos implementar un modelo KNN siguiendo los pasos a continuación:
- Cargar los datos
- Inicializar el valor de k
- Para obtener la clase predicha, iterar desde 1 hasta el número total de puntos de datos de entrenamiento
- Calcular la distancia entre pruebas datos y cada fila de datos de entrenamiento. Aquí usaremos la distancia euclidiana como nuestra métrica de distancia, ya que es el método más popular. Las otras métricas que se pueden utilizar son Chebyshev, coseno, etc.
- Ordene las distancias calculadas en orden ascendente según los valores de distancia
- Obtenga las primeras k filas de la matriz ordenada
- Obtenga la clase más frecuente de estas filas
- Devuelva la clase predicha
Implementación en Python desde cero
Usaremos el popular conjunto de datos Iris para construir nuestro modelo KNN. Puede descargarlo desde aquí.
Comparando nuestro modelo con scikit-learn
Podemos ver que ambos modelos predijeron la misma clase (Iris- virginica ) y los mismos vecinos más cercanos (). Por lo tanto, podemos concluir que nuestro modelo se ejecuta como se esperaba.
Implementación de kNN en R
Paso 1: Importar los datos
Paso 2: Verificar los datos y calcular el resumen de datos
Salida
Paso 3: dividir los datos
Paso 4: calcular la distancia euclidiana
Paso 5: escribir la función para predecir kNN
Paso 6: calcular la etiqueta (nombre) para K = 1
Salida
For K=1 "Iris-virginica"
De la misma manera, puede calcular otros valores de K.
Comparando nuestra función de predicción kNN con la biblioteca «Class»
Salida
For K=1 "Iris-virginica"
Podemos ver que ambos modelos predijeron la misma clase (Iris-virginica).
Notas finales
El algoritmo KNN es uno de los algoritmos de clasificación más simples. Incluso con tal simplicidad, puede dar resultados altamente competitivos. El algoritmo KNN también se puede utilizar para problemas de regresión. La única diferencia de la metodología discutida se utilizará promedios de los vecinos más cercanos en lugar de votar a los vecinos más cercanos. KNN se puede codificar en una sola línea en R. Todavía tengo que explorar cómo podemos usar el algoritmo KNN en SAS.
¿Le resultó útil el artículo? ¿Ha utilizado alguna otra herramienta de aprendizaje automático recientemente? ¿Planea utilizar KNN en alguno de sus problemas comerciales? En caso afirmativo, comparta con nosotros cómo planea hacerlo.