注:この記事は2014年10月10日に最初に公開され、 2018年3月27日
概要
- 最も人気のある機械学習アルゴリズムの1つであるk最近傍法(KNN)を理解する
- kNNの動作を学ぶpythonで
- 簡単にkの正しい値を選択してください
はじめに
4年間でデータサイエンスのキャリアの中で、80%以上の分類モデルと、わずか15〜20%の回帰モデルを構築しました。これらの比率は、業界全体で多かれ少なかれ一般化することができます。分類モデルに対するこのバイアスの背後にある理由は、ほとんどの分析上の問題が意思決定を伴うためです。
たとえば、顧客Xをターゲットにする場合、顧客は属性を付けるかどうかを決定します。顧客の可能性が高いかどうかなど、デジタルキャンペーン。これらの分析はより洞察に満ちており、実装ロードマップに直接リンクされています。

この記事では、K最近傍法(KNN)と呼ばれるもう1つの広く使用されている機械学習分類手法について説明します。主に、アルゴリズムがどのように機能し、入力パラメーターが出力/予測にどのように影響するかに焦点を当てます。
注:ビデオを通じて学習することを好む人は、無料コース–K-を通じて同じことを学ぶことができます。 PythonとRの最近傍(KNN)アルゴリズム。データサイエンスと機械学習の完全な初心者の方は、認定BlackBeltプログラムをご覧ください–
- 認定AI & ML Blackbelt +プログラム
目次
- KNNアルゴリズムはいつ使用しますか?
- どのようにKNNアルゴリズムは機能しますか?
- 係数Kを選択するにはどうすればよいですか?
- 分解–KNNの疑似コード
- Pythonでの最初からの実装
- モデルとscikit-learnの比較
KNNアルゴリズムはいつ使用しますか?
KNNは両方に使用できます分類と回帰の予測問題。ただし、業界の分類問題でより広く使用されています。テクニックを評価するために、私たちは一般的に3つの重要な側面を調べます:
1。出力の解釈のしやすさ
2。計算時間
3。予測力
KNNをスケールに配置するためのいくつかの例を見てみましょう:
 KNNアルゴリズムは、考慮事項のすべてのパラメーターにわたって公平です。解釈が簡単で計算時間が短いため、一般的に使用されます。
KNNアルゴリズムは、考慮事項のすべてのパラメーターにわたって公平です。解釈が簡単で計算時間が短いため、一般的に使用されます。
KNNアルゴリズムはどのように機能しますか?
簡単なケースを見てみましょう。このアルゴリズムを理解してください。以下は、赤い円(RC)と緑の四角(GS)の広がりです:
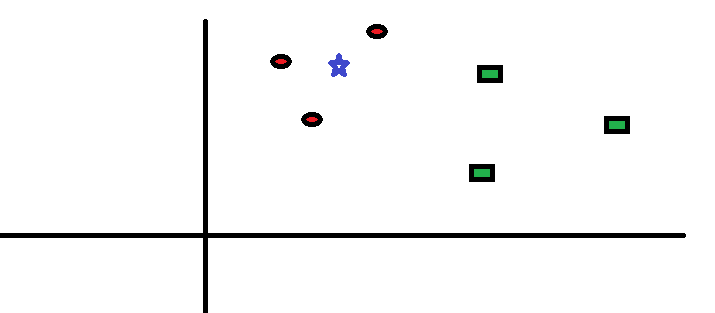 あなたは調べるつもりです青い星(BS)のクラス。 BSはRCまたはGSのいずれかであり、他には何もありません。 「K」はKNNアルゴリズムであり、投票を希望する最近傍法です。たとえば、K = 3とします。したがって、BSを中心として、平面上の3つのデータポイントのみを囲むのと同じ大きさの円を作成します。 。詳細については、次の図を参照してください。
あなたは調べるつもりです青い星(BS)のクラス。 BSはRCまたはGSのいずれかであり、他には何もありません。 「K」はKNNアルゴリズムであり、投票を希望する最近傍法です。たとえば、K = 3とします。したがって、BSを中心として、平面上の3つのデータポイントのみを囲むのと同じ大きさの円を作成します。 。詳細については、次の図を参照してください。
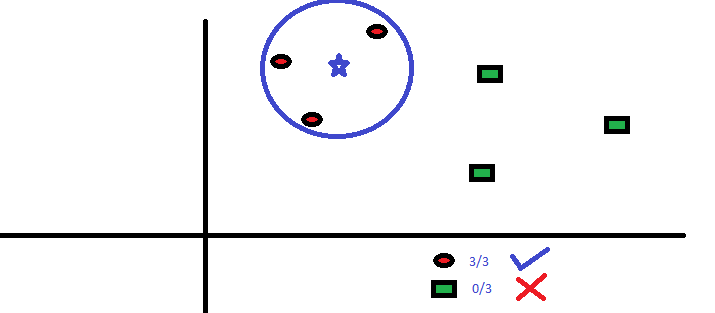 BSに最も近い3つのポイントはすべてRCです。したがって、信頼水準が高い場合、BSはクラスRCに属する必要があると言えます。ここでは、最近傍からの3票すべてがRCに投票されたため、選択が非常に明白になりました。パラメーターKの選択は、このアルゴリズムで非常に重要です。 。次に、最良のKを結論付けるために考慮すべき要素を理解します。
BSに最も近い3つのポイントはすべてRCです。したがって、信頼水準が高い場合、BSはクラスRCに属する必要があると言えます。ここでは、最近傍からの3票すべてがRCに投票されたため、選択が非常に明白になりました。パラメーターKの選択は、このアルゴリズムで非常に重要です。 。次に、最良のKを結論付けるために考慮すべき要素を理解します。
要素Kを選択するにはどうすればよいですか?
最初に、アルゴリズムでKが正確に何に影響するかを理解してみましょう。最後の例を見ると、6つのトレーニング観測値すべてが一定のままであり、与えられたK値で、各クラスの境界を作成できます。これらの境界は、RCをGSから分離します。同様に、クラスの境界に対する値「K」の影響を見てみましょう。以下は、Kの値が異なる2つのクラスを分離する異なる境界です。
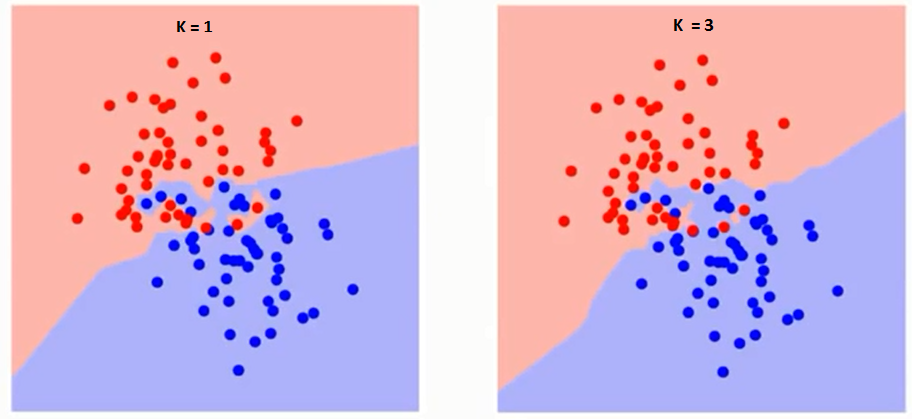
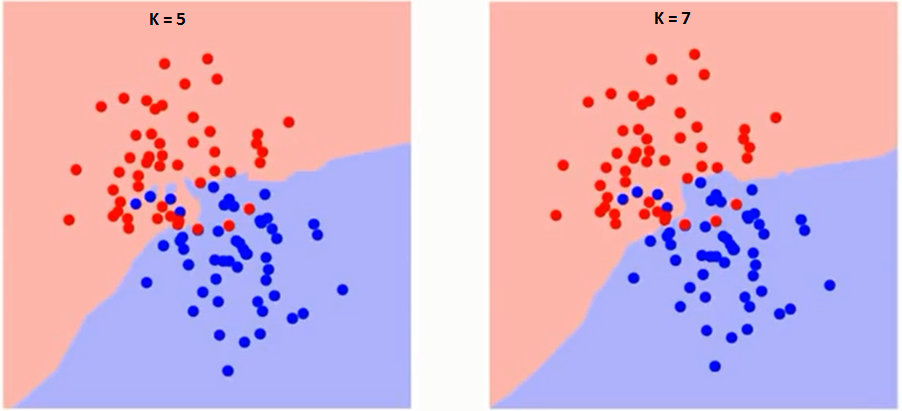
注意深く見ると、 Kの値が増加すると、境界は滑らかになります。Kが無限大に増加すると、全体の過半数に応じて、最終的にすべて青またはすべて赤になります。トレーニングエラー率と検証エラー率は、異なるK値にアクセスするために必要な2つのパラメーターです。以下は、Kの値を変化させた場合のトレーニングエラー率の曲線です:
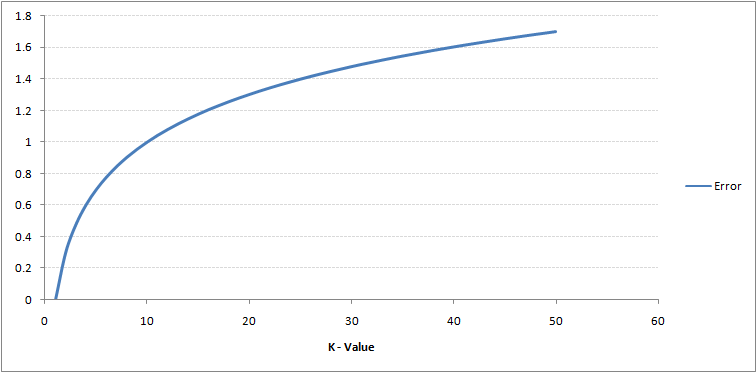 ご覧のとおり、 K = 1でのエラー率は、トレーニングサンプルでは常にゼロです。これは、トレーニングデータポイントに最も近いポイントがそれ自体であるためです。したがって、予測はK = 1で常に正確です。検証エラー曲線が類似している場合、Kの選択は1になります。以下は、Kの値を変化させた検証エラー曲線です。
ご覧のとおり、 K = 1でのエラー率は、トレーニングサンプルでは常にゼロです。これは、トレーニングデータポイントに最も近いポイントがそれ自体であるためです。したがって、予測はK = 1で常に正確です。検証エラー曲線が類似している場合、Kの選択は1になります。以下は、Kの値を変化させた検証エラー曲線です。
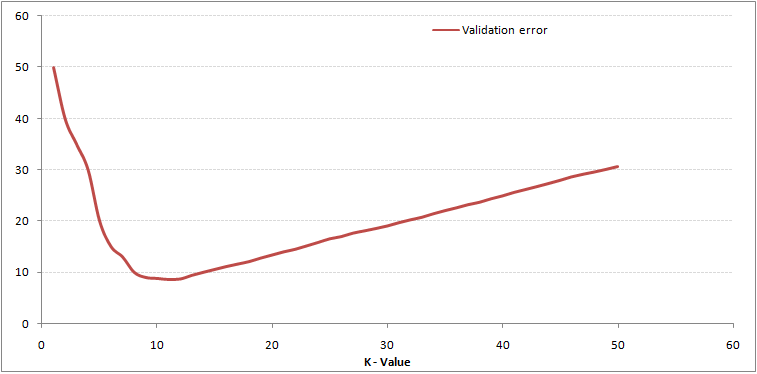 これにより、ストーリーがより明確になります。 K = 1では、境界をオーバーフィットしていました。したがって、エラー率は最初に減少し、最小に達します。最小点の後、Kの増加とともに増加します。Kの最適値を取得するために、トレーニングと検証を初期データセットから分離できます。次に、検証誤差曲線をプロットして、Kの最適値を取得します。このKの値は、すべての予測に使用する必要があります。
これにより、ストーリーがより明確になります。 K = 1では、境界をオーバーフィットしていました。したがって、エラー率は最初に減少し、最小に達します。最小点の後、Kの増加とともに増加します。Kの最適値を取得するために、トレーニングと検証を初期データセットから分離できます。次に、検証誤差曲線をプロットして、Kの最適値を取得します。このKの値は、すべての予測に使用する必要があります。
上記の内容は、無料コースであるK最近傍法を使用してより直感的に理解できます。 KNN)PythonとRのアルゴリズム
分解–KNNの疑似コード
次の手順に従って、KNNモデルを実装できます。
- データをロードする
- kの値を初期化する
- 予測されたクラスを取得するには、1からトレーニングデータポイントの総数まで繰り返します
- テスト間の距離を計算しますデータとトレーニングデータの各行。ここでは、ユークリッド距離が最も一般的な方法であるため、距離メトリックとして使用します。使用できる他のメトリックは、Chebyshev、cosineなどです。
- 距離値に基づいて計算された距離を昇順で並べ替えます
- 並べ替えられた配列から上位k行を取得します
- これらの行の最も頻繁なクラスを取得する
- 予測されたクラスを返す
Pythonでの実装を最初から行う
KNNモデルの構築には人気のあるアイリスデータセットを使用します。ここからダウンロードできます。
モデルとscikit-learnの比較
両方のモデルが同じクラスを予測したことがわかります( Iris- virginica )および同じ最近傍()。したがって、モデルは期待どおりに実行されていると結論付けることができます。
RでのkNNの実装
ステップ1:データのインポート
ステップ2:データの確認とデータサマリーの計算
出力
ステップ3:データの分割
ステップ4:計算ユークリッド距離
ステップ5:kNNを予測する関数の記述
ステップ6:K = 1のラベル(名前)の計算
出力
For K=1 "Iris-virginica"
同様に、Kの他の値を計算できます。
kNN予測関数と「クラス」ライブラリの比較
出力
For K=1 "Iris-virginica"
両方が確認できますモデルは同じクラス( Iris-virginica)を予測しました。
エンドノート
KNNアルゴリズムは、最も単純な分類アルゴリズムの1つです。このような単純さにより、非常に競争力のある結果が得られます。KNNアルゴリズムは、回帰問題にも使用できます。唯一の違いは議論された方法論から、最も近い隣人から投票するのではなく、最も近い隣人の平均を使用するでしょう。 KNNはRで1行でコーディングできます。SASでKNNアルゴリズムを使用する方法についてはまだ調べていません。
この記事は役に立ちましたか?最近、他の機械学習ツールを使用しましたか?ビジネス上の問題でKNNを使用する予定はありますか?はいの場合は、どのように取り組む予定かをお知らせください。