Remarque: Cet article a été initialement publié le 10 octobre 2014 et mis à jour le 27 mars 2018
Présentation
- Comprendre k le plus proche voisin (KNN) – lun des algorithmes dapprentissage automatique les plus populaires
- Découvrez le fonctionnement de kNN en python
- Choisissez la bonne valeur de k en termes simples
Introduction
Dans les quatre ans de ma carrière en science des données, jai construit plus de 80% de modèles de classification et seulement 15 à 20% de modèles de régression. Ces ratios peuvent être plus ou moins généralisés dans toute lindustrie. La raison de ce biais en faveur des modèles de classification est que la plupart des problèmes analytiques impliquent de prendre une décision.
Par exemple, un client attirera-t-il ou non, si nous ciblons le client X pour campagnes numériques, que le client ait un potentiel élevé ou non, etc. Ces analyses sont plus perspicaces et directement liées à une feuille de route de mise en œuvre.

Dans cet article, nous parlerons dune autre technique de classification dapprentissage automatique largement utilisée appelée K-plus proche voisins (KNN). Notre objectif sera principalement de savoir comment fonctionne lalgorithme et comment le paramètre dentrée affecte la sortie / prédiction.
Remarque: les personnes qui préfèrent apprendre à travers des vidéos peuvent apprendre la même chose grâce à notre cours gratuit – K- Algorithme KNN (Nearest Neighbours) en Python et R. Et si vous êtes un débutant complet en science des données et en apprentissage automatique, consultez notre programme Certified BlackBelt –
- Certified AI & ML Blackbelt + Program
Table des matières
- Quand utilisons-nous lalgorithme KNN?
- Comment fonctionne le Lalgorithme KNN fonctionne?
- Comment choisissons-nous le facteur K?
- Décomposer – Pseudo Code de KNN
- Implémentation en Python à partir de zéro
- Comparaison de notre modèle avec scikit-learn
Quand utilisons-nous lalgorithme KNN?
KNN peut être utilisé pour les deux problèmes prédictifs de classification et de régression. Cependant, il est plus largement utilisé dans les problèmes de classification dans lindustrie. Pour évaluer toute technique, nous examinons généralement 3 aspects importants:
1. Facilité dinterprétation de la sortie
2. Temps de calcul
3. Predictive Power
Prenons quelques exemples pour placer KNN dans léchelle:
 Lalgorithme KNN correspond à tous les paramètres de considérations. Il est couramment utilisé pour sa facilité dinterprétation et son temps de calcul réduit.
Lalgorithme KNN correspond à tous les paramètres de considérations. Il est couramment utilisé pour sa facilité dinterprétation et son temps de calcul réduit.
Comment fonctionne lalgorithme KNN?
Prenons un cas simple pour comprendre cet algorithme. Voici une série de cercles rouges (RC) et de carrés verts (GS):
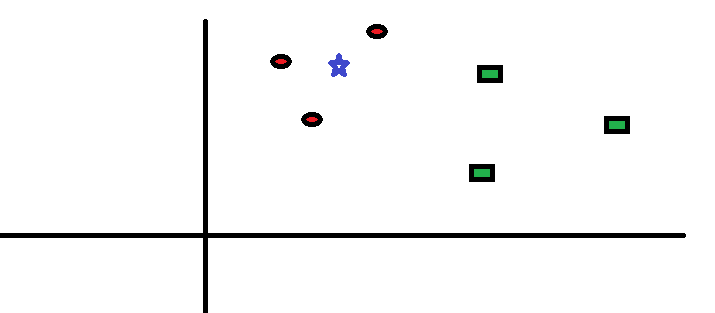 Vous avez lintention de le savoir la classe de létoile bleue (BS). BS peut être RC ou GS et rien dautre. Lalgorithme « K » est KNN est le voisin le plus proche duquel nous souhaitons prendre le vote. Disons K = 3. Par conséquent, nous allons maintenant faire un cercle avec BS comme centre tout aussi grand que pour ne contenir que trois points de données sur le plan . Reportez-vous au diagramme suivant pour plus de détails:
Vous avez lintention de le savoir la classe de létoile bleue (BS). BS peut être RC ou GS et rien dautre. Lalgorithme « K » est KNN est le voisin le plus proche duquel nous souhaitons prendre le vote. Disons K = 3. Par conséquent, nous allons maintenant faire un cercle avec BS comme centre tout aussi grand que pour ne contenir que trois points de données sur le plan . Reportez-vous au diagramme suivant pour plus de détails:
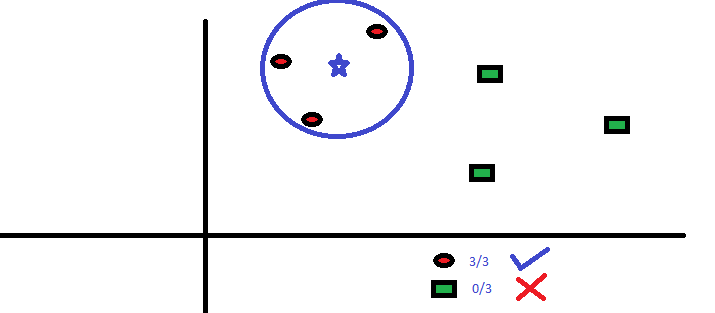 Les trois points les plus proches de BS sont tous RC. Par conséquent, avec un bon niveau de confiance, on peut dire que la BS doit appartenir à la classe RC. Ici, le choix est devenu très évident car les trois votes du plus proche voisin sont allés à RC. Le choix du paramètre K est très crucial dans cet algorithme . Ensuite, nous comprendrons quels sont les facteurs à considérer pour conclure au meilleur K.
Les trois points les plus proches de BS sont tous RC. Par conséquent, avec un bon niveau de confiance, on peut dire que la BS doit appartenir à la classe RC. Ici, le choix est devenu très évident car les trois votes du plus proche voisin sont allés à RC. Le choix du paramètre K est très crucial dans cet algorithme . Ensuite, nous comprendrons quels sont les facteurs à considérer pour conclure au meilleur K.
Comment choisir le facteur K?
Essayons dabord de comprendre ce que K influence exactement dans lalgorithme. Si nous voyons le dernier exemple, étant donné que toutes les 6 observations dentraînement restent constantes, avec une valeur K donnée, nous pouvons faire des limites de chaque classe. Les frontières sépareront RC de GS. De la même manière, essayons de voir leffet de la valeur « K » sur les limites des classes. Voici les différentes limites séparant les deux classes avec des valeurs différentes de K.
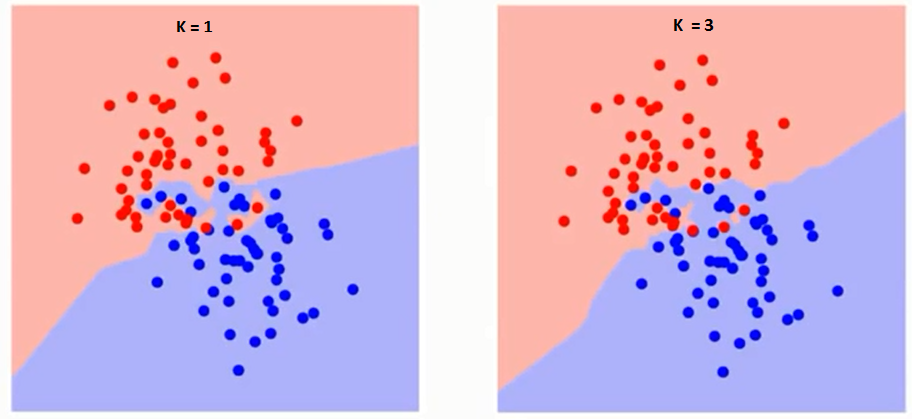
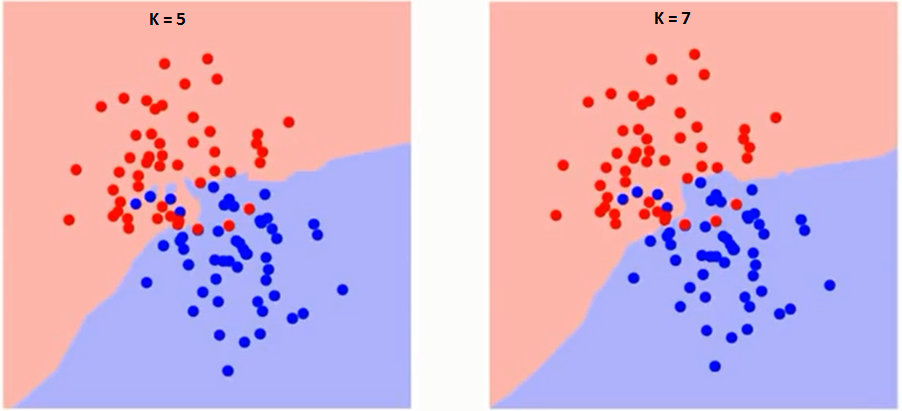
Si vous regardez attentivement, vous pouvez voir que la limite devient plus lisse avec laugmentation de la valeur de K. Avec laugmentation de K à linfini, il devient finalement tout bleu ou tout rouge en fonction de la majorité totale.Le taux derreur dapprentissage et le taux derreur de validation sont deux paramètres dont nous avons besoin pour accéder à des valeurs K différentes. Voici la courbe du taux derreur de formation avec une valeur variable de K:
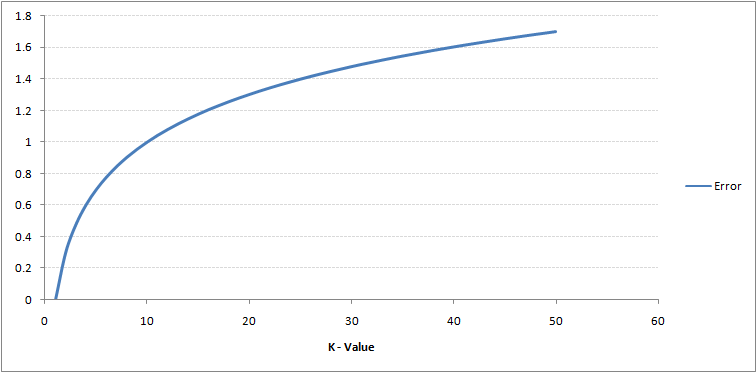 Comme vous pouvez le voir, le le taux derreur à K = 1 est toujours nul pour léchantillon dapprentissage.En effet, le point le plus proche de tout point de données dapprentissage est lui-même, doù la précision de la prédiction avec K = 1. Si la courbe derreur de validation avait été similaire, notre choix de K aurait été 1. Voici la courbe derreur de validation avec une valeur variable de K:
Comme vous pouvez le voir, le le taux derreur à K = 1 est toujours nul pour léchantillon dapprentissage.En effet, le point le plus proche de tout point de données dapprentissage est lui-même, doù la précision de la prédiction avec K = 1. Si la courbe derreur de validation avait été similaire, notre choix de K aurait été 1. Voici la courbe derreur de validation avec une valeur variable de K:
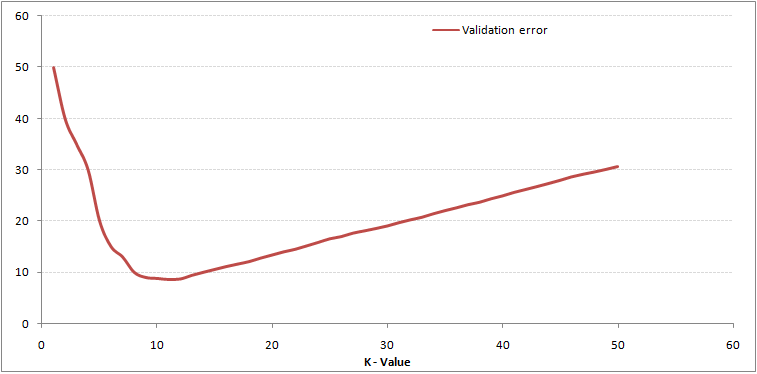 Cela rend lhistoire plus claire. À K = 1, nous sur-ajustions les limites. Par conséquent, le taux derreur diminue initialement et atteint un minimum. Après le point de minima, il augmente ensuite avec laugmentation de K. Pour obtenir la valeur optimale de K, vous pouvez séparer la formation et la validation de lensemble de données initial. Tracez maintenant la courbe derreur de validation pour obtenir la valeur optimale de K. Cette valeur de K doit être utilisée pour toutes les prédictions.
Cela rend lhistoire plus claire. À K = 1, nous sur-ajustions les limites. Par conséquent, le taux derreur diminue initialement et atteint un minimum. Après le point de minima, il augmente ensuite avec laugmentation de K. Pour obtenir la valeur optimale de K, vous pouvez séparer la formation et la validation de lensemble de données initial. Tracez maintenant la courbe derreur de validation pour obtenir la valeur optimale de K. Cette valeur de K doit être utilisée pour toutes les prédictions.
Le contenu ci-dessus peut être compris plus intuitivement en utilisant notre cours gratuit – K-Nearest Neighbours ( KNN) Algorithme en Python et R
Décomposer – Pseudo Code de KNN
Nous pouvons implémenter un modèle KNN en suivant les étapes ci-dessous:
- Charger les données
- Initialiser la valeur de k
- Pour obtenir la classe prédite, itérer de 1 au nombre total de points de données dentraînement
- Calculer la distance entre les tests données et chaque ligne de données dentraînement. Ici, nous utiliserons la distance euclidienne comme mesure de distance, car cest la méthode la plus populaire. Les autres métriques pouvant être utilisées sont Chebyshev, cosinus, etc.
- Trier les distances calculées par ordre croissant en fonction des valeurs de distance
- Obtenir les k premières lignes du tableau trié
- Obtenir la classe la plus fréquente de ces lignes
- Renvoyer la classe prédite
Implémentation en Python à partir de zéro
Nous utiliserons le jeu de données Iris populaire pour construire notre modèle KNN. Vous pouvez le télécharger ici.
Comparaison de notre modèle avec scikit-learn
Nous pouvons voir que les deux modèles prédisaient la même classe (Iris- virginica ) et les mêmes voisins les plus proches (). Nous pouvons donc conclure que notre modèle fonctionne comme prévu.
Implémentation de kNN dans R
Étape 1: Importation des données
Étape 2: Vérification des données et calcul du résumé des données
Sortie
Étape 3: Fractionnement des données
Étape 4: Calcul la distance euclidienne
Étape 5: Écriture de la fonction pour prédire kNN
Étape 6: Calcul de létiquette (Nom) pour K = 1
Sortie
For K=1 "Iris-virginica"
De la même manière, vous pouvez calculer pour dautres valeurs de K.
Comparaison de notre fonction de prédicteur kNN avec la bibliothèque « Class »
Sortie
For K=1 "Iris-virginica"
Nous pouvons voir que les deux modèles prédisaient la même classe (Iris-virginica).
Notes de fin
Lalgorithme KNN est lun des algorithmes de classification les plus simples. Même avec une telle simplicité, il peut donner des résultats très compétitifs. Lalgorithme KNN peut également être utilisé pour les problèmes de régression. La seule différence de la méthodologie discutée utilisera des moyennes des voisins les plus proches plutôt que de voter des voisins les plus proches. KNN peut être codé en une seule ligne sur R. Je nai pas encore exploré comment utiliser lalgorithme KNN sur SAS.
Avez-vous trouvé cet article utile? Avez-vous récemment utilisé un autre outil dapprentissage automatique? Avez-vous lintention dutiliser KNN dans lun de vos problèmes commerciaux? Si oui, expliquez avec nous comment vous comptez procéder.